- 一个真正的CMS
- 后端需要实现的效果
- 前端需要实现的效果
- 后端的实际写法
- API 使用的依赖包
- API 被调用时返回处理后的 HTML 或原 Markdown 内容
- 给 API 添加管理后台入口
- 保存文件和删除文件
- 前端的实际写法
- 调用 API 和渲染 Markdown
- 渲染 Markdown 时的注意事项
- 添加页内平滑滚动效果
- 大概是这么个效果
- 心得体会
一个真正的CMS
GitHub 项目地址: https://github.com/c53hzn/april-cms
去年开始学习使用 Nuxt 的时候,看了很多关于 Headless CMS 的介绍,按我的理解,就是 不带前端页面设计的内容管理系统 ,研究了一下这类的项目以及相关使用方法,自己也尝试使用了一下,但是没有坚持到底,还是想不依赖这些外部服务来构建自己的网站。不过评论系统和访客统计还是得用外部服务,因为静态网站服务器做不到这些。
后来我自己写出了可以用作 CMS 的 API,可以参见 如何使用Nuxt建立个人博客。
这个 API 让我可以只需更新 Markdown 文章,再使用 Nuxt 的生成静态页面的功能就可以更新我的网站。通常我是用 Sublime Text 这个编辑器来编写代码的,它可以在左边显示工程文件,切换起来也挺方便的。
可是人类就是喜欢自找麻烦。
by 我
我想要一个有界面的 CMS,能新建,能修改,能读取,能保存,能删除。但是我只要操作 Markdown 文件,而不要任何数据库。
我觉得我能做到。
写了个英文版 Write a control panel for my API-based CMS for Nuxt,大家随便看看就好。
后端需要实现的效果
由于我原本的 API 是用 Node 的 express 写的,所以还是想在此基础上继续精进,那么就需要掌握 Node 服务器的一些用法,比如:
- 让
API读取静态 HTML 页面,使浏览器能显示CMS的 UI 界面。 - 开启
API的时候自动打开浏览器访问入口,也就是前一项的 UI 界面。 - 让
API能接受浏览器(客户端)传回来的数据,并保存到本地。 - 让
API接受浏览器传回来的数据,然后删除相关文件。
前端需要实现的效果
我之前还有一个在 CodePen 上的 Markdown Previewer 的项目,半年来浏览量一只手就能数得清,就这么放着也挺可惜,不如拿来这里用一用。
CodePen 项目的渲染效果是用 marked 来实现的的,而我的 API 里面是用 markdown-it 来做渲染的,为了统一写法,得把渲染的方式改成 Markdown-it。
这个项目主体是用 jQuery 写的,我最终决定继续用 jQuery 来写前端的页面交互。
那么我们就需要解决以下的问题:
- 读取
API传来的文章列表并渲染到文章列表区 - 读取
API传来的文章内容并渲染文章的标题、标签、描述、关联文章、正文到各个输入框,以及最重要的Markdown编辑器 - 每当
Markdown编辑器有更新时,预览区也要跟着更新,预览区还应该有代码高亮和一般样式渲染 - 点击
Save post的时候,页面要检查各个输入框是否都有内容,没有则alert让填写内容,有的话再检查文章是否已存在,存在则confirm要不要更新,不存在则confirm要不要创建。 - 点击
Delete post的时候,页面要检查slug在文章列表里是否存在,不存在则alert说没东西可删,如果存在则要confirm是否真的删除。 - 键盘按下
ctrl+enter触发保存,效果等同于点击Save post。 - 当确认要更新或创建的时候,浏览器使用
jQuery的post方法提交内容到服务器,并获取提交结果,反映到浏览器 - 当确认要删除的时候,浏览器使用
jQuery的post方法提交要删除的slug到服务器,并获取删除结果,反映到浏览器。
并且这些要在一个页面里完成。
后端的实际写法
API 使用的依赖包
先 require 一下各个依赖。
var express = require("express");
var fs = require("fs");
var fm = require('front-matter');
var hljs = require('highlight.js');
var markdownIt = require('markdown-it');
var markdownItToc = require('markdown-it-toc');
var open = require("open");
var config = require(__dirname+"\\config.js");
var app = express();
var md = markdownIt({
html: false, // 在源码中启用 HTML 标签
xhtmlOut: false, // 使用 '/' 来闭合单标签 (比如 <br />)。
breaks: false, // 转换段落里的 '\n' 到 <br>。
langPrefix: 'language-', // 给围栏代码块的 CSS 语言前缀。对于额外的高亮代码非常有用。
linkify: false, // 将类似 URL 的文本自动转换为链接。
typographer: false,
quotes: '“”‘’',
highlight: function (str, lang) {
if (lang && hljs.getLanguage(lang)) {
try {
return hljs.highlight(lang, str).value;
} catch (__) {}
}
return ''; // 使用额外的默认转义
}
});
md.use(markdownItToc);
这里有个 config 是我额外加的配置文件,里面的内容也很简单
var config = {
isSlugUseDate: false,
blogPath: __dirname + '\\blog',
imgPath: __dirname + '\\img\\blog'
};
module.exports = config;
这个 config 是为了控制 CMS 里面的 Markdown 文件和图片文件的路径,以及 API 返回的 slug 是否使用日期而加的。如果 slug 使用日期,就会是一个长的 slug,比如 2020-04-19-editor-for-my-cms-of-my-nuxt-blog,如果不使用日期,就会是一个短的 slug,比如 editor-for-my-cms-of-my-nuxt-blog,那么相应的,博客文章的 URL 也会有长短之分,就看大家自己喜欢哪一种了。
API 被调用时返回处理后的 HTML 或原 Markdown 内容
在 API 的入口文件 app.js 里面做一下配置,这样就可以控制返回的文章正文是 Markdown 还是经过处理的 HTML 内容,同时 API 也会按照 config 里面对 slug 的要求,根据所请求的 slug 返回内容。
var slugToFileName = function(slug,isSlugUseDate) {
var result = "";
if (isSlugUseDate) {
result = slug+".md";
} else {
var files = fs.readdirSync(config.blogPath);
for (let i = 0; i < files.length; i++) {
let tempSlug = files[i].substring(11,files[i].length);
if (tempSlug == slug+".md") {
result = files[i];
break;
}
}
}
return result;
}
var fileNameToSlug = function(filename,isSlugUseDate) {
if (isSlugUseDate) {
return filename.substring(0,filename.length-3);
} else {
return filename.substring(11,filename.length-3);
}
}
var singleBlog = function(fullPath,slug,isContentRequired,isMD,isDev) {
var blog = {};
var content = fm(fs.readFileSync(fullPath, "utf8"));
blog = content.attributes;
blog.slug = slug;
var fullFilename = fullPath.replace(config.blogPath+"\\","");
blog.date = fullFilename.substring(0,10);
if (isContentRequired && !isMD) {
let html = md.render('@[toc]( )\n' + content.body);
//if isDev then use absolute path for images
if (isDev) {
html = html.replace(/src=\"(\/)?img/g,"src=\"http://127.0.0.1:4000/img");
}
// add class "hljs" for dark theme rendering
blog.content = html.replace(/\<pre/g,"<pre class='hljs'");
} else if (isContentRequired && isMD) {
blog.content = content.body;
}
return blog;
}
//return blog related contents
app.get("/blog", function(req, res) {
// allow cross orign access
res.header('Access-Control-Allow-Origin', '*');
var blogPath = config.blogPath;
var imgPath = config.imgPath;
var files = fs.readdirSync(blogPath);
var json = {};// result to be returned
var qSlug = req.query.slug || "";
var qTag = req.query.tag || "";
var qImg = req.query.img || "";
var qIsMD = req.query.ismd == "true";
var qIsDev = req.query.isdev == "true";
var isSlugUseDate = (req.query.iseditor == "true")?true:config.isSlugUseDate;
if (qSlug) {// with blog slug query
json = singleBlog(`${blogPath}\\${slugToFileName(qSlug,isSlugUseDate)}`,qSlug,true,qIsMD,qIsDev);
for (let k = 0; k < files.length; k++) {// add prev and next blog
if (qSlug == fileNameToSlug(files[k],isSlugUseDate)) {
if (k === 0) {
json.next = fileNameToSlug(files[k+1],isSlugUseDate);
} else if (k === files.length-1) {
json.prev = fileNameToSlug(files[k-1],isSlugUseDate);
} else {
json.prev = fileNameToSlug(files[k-1],isSlugUseDate);
json.next = fileNameToSlug(files[k+1],isSlugUseDate);
}
}
}
} else if (qTag) {// with tag query
if (qTag == "all_tags") {// returns list of all available tags
json.tags = {};
for (let i = 0; i < files.length; i++) {
let blogPost = singleBlog(blogPath+"\\"+files[i],fileNameToSlug(files[i],isSlugUseDate));
let tags = blogPost.tags || ['none'];
let entry = {
title: blogPost.title,
slug: blogPost.slug
};
for (let j = 0; j < tags.length; j++) {
if (json.tags[tags[j]]) {
json.tags[tags[j]]++;
} else {
json.tags[tags[j]] = 1;
}
}
}
} else {// returns blog list of specific tag
json.blogs = [];
for (let i = 0; i < files.length; i++) {
let blogPost = singleBlog(blogPath+"\\"+files[i],fileNameToSlug(files[i],isSlugUseDate));
let tags = blogPost.tags || ['none'];
let entry = {
title: blogPost.title,
slug: blogPost.slug
};
for (let j = 0; j < tags.length; j++) {
if (tags[j] == qTag) {
json.blogs.unshift(blogPost);
}
}
}
}
} else if (qImg) {// with img query
if (qImg == "all_imgs") {
json.imgs = {};
var imgFolders = fs.readdirSync(imgPath);
for (let i = 0; i < imgFolders.length; i++) {
let imgs = fs.readdirSync(imgPath+"\\"+imgFolders[i]);
json.imgs[imgFolders[i]] = imgs;
}
}
} else {//without requirement, returns list of all blogs
json.blogs = [];
for (let i = 0; i < files.length; i++) {
let blogPost = singleBlog(blogPath+"\\"+files[i],fileNameToSlug(files[i],isSlugUseDate));
json.blogs.unshift(blogPost);
}
}
res.send(json);
});
app.get("/config", function(req, res) {
// allow cross orign access
res.header('Access-Control-Allow-Origin', '*');
res.send(config);
});
给 API 添加管理后台入口
我在 API 所在的文件夹新建了 app.html,以作为 UI 界面的入口,而要让 API 可以访问这个静态页面,就要像下面这样写
//return blog content editor page
app.use(express.static(__dirname));
app.get("/", function(req, res) {
// allow cross orign access
res.header('Access-Control-Allow-Origin', '*');
res.sendFile(__dirname+"\\app.html");
});
/* nuxt is using port 3000, so choose another one */
app.listen(4000, () => {
console.log("express server running at http://127.0.0.1:4000")
});
那么这个 CMS 的入口链接就是 http://127.0.0.1:4000/ 了。
为了能在开启 API 的时候自动打开浏览器并访问该地址,还需要使用 open 这个 npm,然后加一行打开浏览器的指令
open("http:127.0.0.1:4000/",{app: "chrome.exe"});
就能直接自动打开浏览器并访问 CMS 的管理界面了。这个界面总共也就一页,所以很好管理。
保存文件和删除文件
之后就是接受浏览器传回来的数据并保存到本地,或者接收浏览器传回的删除指令,删除相关文件。
//api to submit post
// Parse URL-encoded bodies (as sent by HTML forms)
app.use(express.urlencoded({ extended: true }));
// Parse JSON bodies (as sent by API clients)
app.use(express.json());
// Access the parse results as request.body
app.post('/savepost', function(req, res){
var obj = req.body;
var fileName = config.blogPath+"\\"+obj.slug+".md";
fs.writeFileSync(fileName, obj.str);
//Client will get status of failure w/o this
//even if data is saved to server successfully
res.send({"status": "success"});
});
// delete post
app.post('/deletepost', function(req, res){
var obj = req.body;
var fileName = config.blogPath+"\\"+obj.slug+".md";
try {
fs.unlinkSync(fileName);
//file removed
} catch(err) {
console.error(err);
}
//Client will get status of failure w/o this
//even if data is saved to server successfully
res.send({"status": "success"});
});
前端的实际写法
调用 API 和渲染 Markdown
具体代码其实没什么好说的,文章列表的 API 是 /blogs,而保存文章的 API 是 /savepost,删除文章的 API 是 /deletepost,获取文章列表可以用 jQuery 的 getJSON 方法,而保存和删除可以用 jQuery 的 post 方法。
从编辑区域获取到 Markdown 之后,用 markdown-it 渲染到右边的预览区域,并且给 markdown-it 添加用来生成锚点链接的 markdown-it-toc 和用来高亮代码的 highlight.js 这两个插件,然后给页面引入 github-markdown 这套用来渲染转化后的 HTML 的 css 以及和 highlight.js 配套的 css,差不多就完工了。
渲染 Markdown 时的注意事项
但是这里可能要注意一下原本在 Node 里使用的模块在引入浏览器时的用法。
原本作为 Node 模块使用的时候,先
var markdownIt = require('markdown-it');
var hljs = require('highlight.js');
var markdownItToc = require('markdown-it-toc');
然后
var md = markdownIt({
html: false,
xhtmlOut: false,
breaks: false,
langPrefix: 'language-',
linkify: false,
typographer: false,
quotes: '“”‘’',
highlight: function (str, lang) {
if (lang && hljs.getLanguage(lang)) {
try {
return hljs.highlight(lang, str).value;
} catch (__) {}
}
return '';
}
});
md.use(markdownItToc);
就可以用来渲染 Markdown 了。
但是在浏览器里用的时候总是报错,这个对象找不到,那个对象也找不到,反正我就是没有对象就是了。
后来才发现,作者在写成浏览器用的版本时,暴露出来的变量名的大小写跟我引用的不一样。
我挨个 js 文件打开,发现markdown-it 在浏览器里的变量名是 markdownit,而用来生成锚点链接的 markdown-it-toc 的变量名是 markdownitTOC,于是我把自己的脚本里面的变量名改成跟原变量名一致,然后就有对象可以用了。
这个问题本来不应该是问题的,实在是让人懊恼。
添加页内平滑滚动效果
由于文章预览区域加了锚点链接,我希望能做到禁止直接跳转 # 开头的锚点链接,而是平滑滚动到相关位置,这个部分的代码如下:
function updatePreview(){
var d = document;
var source = $("#editor").val();
var html = "\t" + md.render('[toc]\n' + source);
html = html.replace(/\<a/g,"<a target='_blank'");
$("#preview").html(html);
//add scrollIntoView to anchor link
var aTags = d.querySelectorAll("a[href]");
for (let i = 0; i < aTags.length; i++) {
if (aTags[i].href.indexOf("#") !== -1) {
aTags[i].onclick = function(e) {
var c = e || event;
c.preventDefault();
var href = aTags[i].href;
var hashPos = href.indexOf("#");
var id = href.substring(hashPos+1, href.length);
d.querySelector("a[id='"+String(id)+"']").scrollIntoView({behavior: "smooth"});
}
}
}
}
大概是这么个效果
需要访问 API 的时候,可以 cd 进入该 API 的文件夹,然后
node app.js
再在浏览器里打开 http://127.0.0.1:4000/ 这个页面,就能看到文章列表,可以增、删、改文章了。参考以下截图
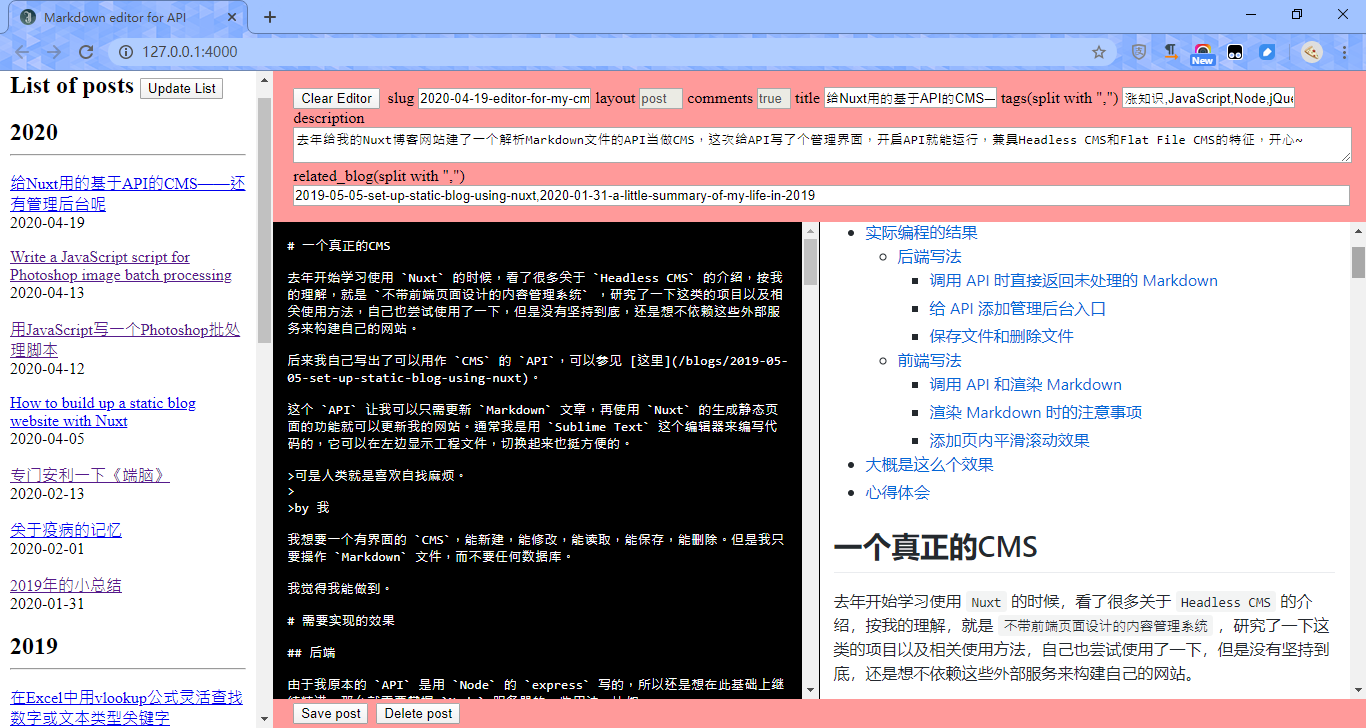
心得体会
今天终于把我心心念念想了一年的东西做出来了,而且只花了一天的时间,真的很开心。
我给它取名叫 April CMS,因为我是在四月里写成的。
做完之后我又研究了下,觉得这个单页面的 CMS 既符合 基于 API 的 Headless CMS 的特征,又符合 Flat File CMS 的特征,也就是 不操作数据库而是操作文本文件的 CMS,感觉好像很高级嘛~
而且预览区和目录区都会随着输入和保存、删除等动作自动更新,写作时无比丝滑顺畅,拿来写文档、写小说啥的好像都不错。
啊,我不知道怎么夸自己才好了。
不说这些肉麻的,总之这次写了个有用的东西,希望以后也能写出更多有用的东西。